Time-frequency (TF) representations provide powerful and intuitive features for the analysis of time series such as audio. But still, generative modeling of audio in the TF domain is a subtle matter. Consequently, neural audio synthesis widely relies on directly modeling the waveform and previous attempts at unconditionally synthesizing audio from neurally generated TF features still struggle to produce audio at satisfying quality. In this contribution, focusing on the short-time Fourier transform, we discuss the challenges that arise in audio synthesis based on generated TF features and how to overcome them.
We demonstrate the potential of deliberate generative TF modeling with TiFGAN, which generates audio successfully using an invertible TF representation and improves on the current state-of-the-art for audio synthesis with GANs. TiFGAN is an adaptation of DCGAN, originally proposed for image generation. The TiFGAN architecture additionally relies on the guidelines and principles for generating short-time Fourier data that we presented in the accompanying paper.
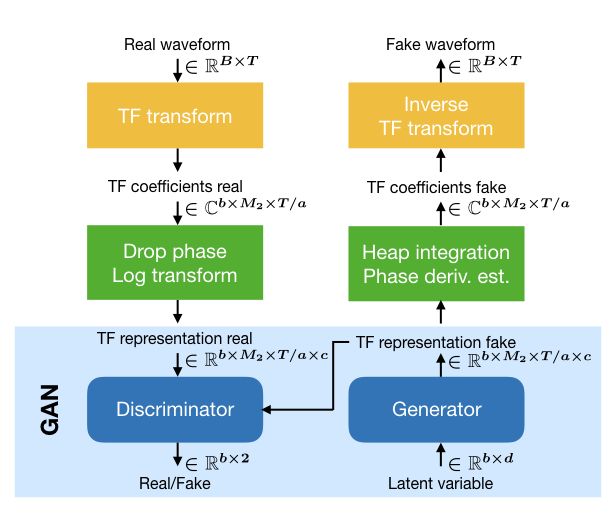
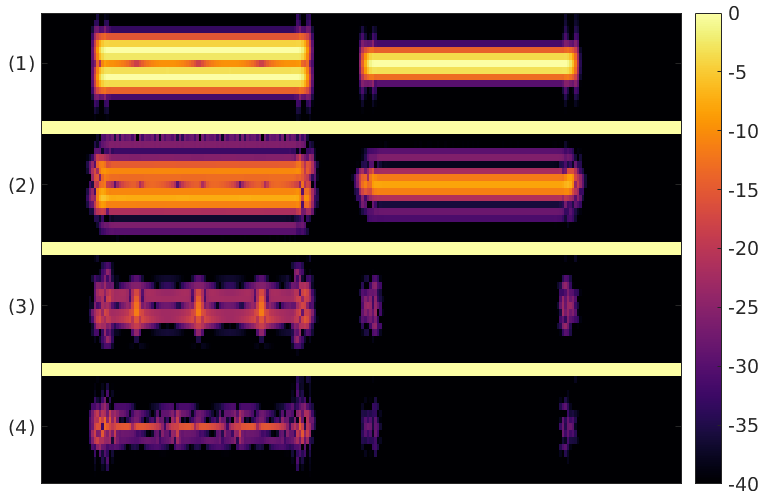
The general architecture for TiFGAN is depicted above. For the purpose of this contribution, we restrict to generating 1 second of audio data, sampled at 16kHz. For the short-time Fourier transform, we chose for the analysis window a (sampled) Gaussian and fix the minimal redundancy that we consider reliable, i.e., M/a = 4 and select a=128, M=512. Since the Nyquist frequency is not expected to hold significant information for the considered signals, we drop it to arrive at a representation size of 256x128, which is well suited to processing using strided convolutions. For the reconstruction of the phase we use phase-gradient heap integration (PGHI) (see Prusa et Al) which requires no iteration, such that reconstruction time is comparable to simply integrating the phase derivatives. For synthesis from the STFT, we use the canonical dual window, precomputed using the Large Time-Frequency Analysis Toolbox (LTFAT).
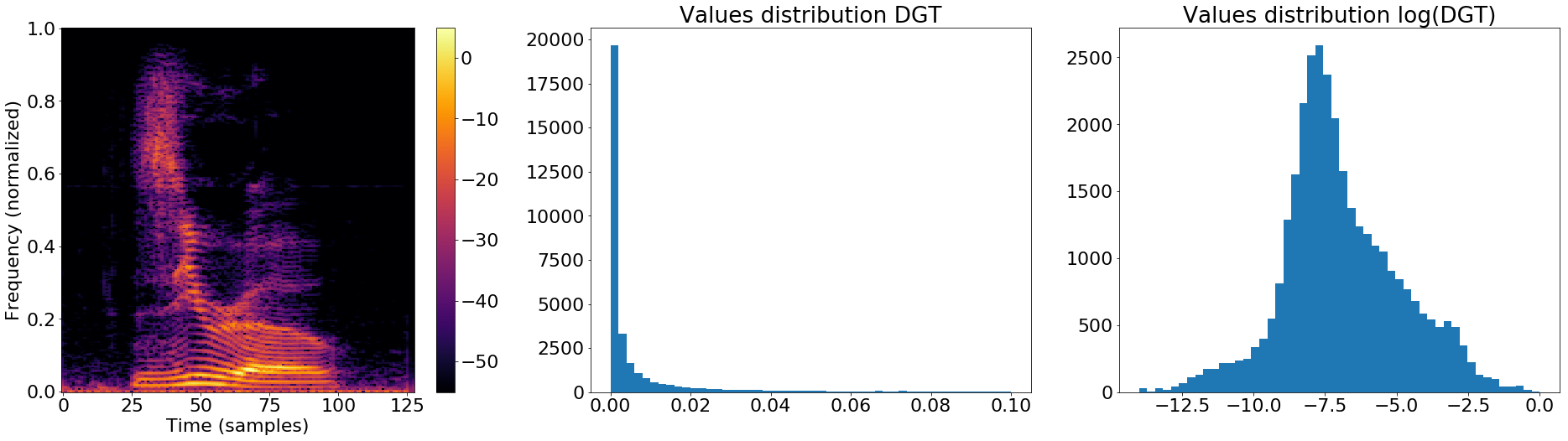
Since the distribution of values in the magnitude of the Short-Time Fourier Transform (STFT) is not well suited for a GAN (see Figure above) we use log-magnitude coefficients. We first normalize the STFT magnitude to have maximum value 1, such that the log-magnitude is confined in (-inf, 0]. Then, the dynamic range of the log-magnitude is limited by clipping at -r (in our experiments r=10), before scaling and shifting to the range of the generator output [-1,1], i.e. dividing by r/2 before adding constant 1.
The network trained to generate log-magnitudes will be referred to as TiFGAN-M. For TiFGAN-M, the phase derivatives are estimated from the generated log-magnitude. Generation of, and synthesis from, the log-magnitude STFT is the main focus of this contribution. Nonetheless, we also trained a variant architecture TiFGAN-MTF for which we additionally provided the time- and frequency-direction derivatives of the (unwrapped, demodulated) phase.